



Welcome to today's blog post, where we'll be discussing the ACID properties of a database. ACID stands for Atomicity, Consistency, Isolation and Durability. ACID properties are usually associated with relational databases such as MySQL and PostgreSQL, but recently NoSQL databases such as MongoDB and Cassandra have also made changes to ensure that they are ACID compliant. In this post, I will break down what each of these properties means and why they're so significant.
If you're a software developer or tech enthusiast who is curious to know how databases are efficient enough to support huge applications such as the likes of Instagram and Github, read on!
Introduction to Transactions
To understand what each of the ACID properties means, first, we need to understand what a database transaction is.
A database transaction refers to a logical unit of work performed within a database management system. It represents a sequence of database operations that are executed as a single, indivisible unit. These operations can include inserting, updating, deleting, or retrieving data from the database.
If you've played around with SQL queries before you would be familiar with how queries are usually executed. Let's take an example of an online retail store.
Let's say the store maintains its inventory data in a table and the order details in another table. Now suppose a customer places an order in the store. This transaction would involve two operations:
updating the inventory quantity, and
recording the order details in the database.
These two operations need to be executed together, that is, it doesn't make sense if for some reason one of these operations fails, and the other one goes through. That would lead to inconsistent data. The typical lifecycle of a transaction would look something like this:
Begin Transaction: The transaction starts, and a transaction identifier is assigned.
Read Data: The system reads the current quantity of the product from the inventory table.
Check Availability: The system checks if there is a sufficient quantity of the product available to fulfill the order. If there is not enough stock, the transaction can be rolled back or an appropriate action can be taken.
Modify Data: If the product is available, the system decreases the quantity by the amount ordered.
Write Data: The updated quantity is written back to the inventory table.
Record Order: The transaction details, such as the customer's information, order date, and product details, are recorded in the orders table.
Commit Transaction: If all the operations within the transaction are successful, the changes are permanently saved by committing the transaction to the database. The inventory quantity is updated, and the order is recorded.
End Transaction: The transaction is officially completed and marked as successful.
In case either of the two operations fails, the transaction is rolled back. This means that all the changes done so far in the transaction are undone. If all the operations in the transaction are executed successfully, the changes done are committed to the database.
Can you think of any different execution methods for how these changes could be committed and rolled back and how that would affect the speed at which transactions are executed? Let's explore two such methods:
Each change made can be written to the database as soon as they're executed. This method would ensure that commits are very fast (since all the changes have already been written to the database), but making a rollback would be very slow since all these changes would have to be undone.
All the changes made can be stored in the system memory. In this case, rollbacks would be very fast, since all that would be required to be done is to erase those changes from memory. But making a commit would be sluggish as all the changes would have to be written to the database one by one after the COMMIT command was executed.
Different databases will usually choose their version of optimizations to handle transactions.
Now that you have a good idea of what transactions are and how they work, let's talk about the ACID properties, which all transactions abide by.
A for Atomicity
We've already encountered how atomicity works in the last section. Let's have a formal introduction to this all-important property of databases for completeness' sake.
Atomicity ensures that a transaction is treated as an indivisible unit of work, where either all the operations within the transaction are completed and committed, or none of them are applied at all. In other words, atomicity guarantees that a transaction is all-or-nothing. The atomicity property of transactions ensures data integrity and consistency. It prevents the database from being left in an inconsistent state if a transaction fails or encounters an error midway. By enforcing atomicity, the database system guarantees that transactions are executed reliably and predictably.
To ensure atomicity, databases often use transaction logs or undo logs. These logs maintain a record of the changes made by a transaction. In case of a failure, the system can use the logs to undo the changes and restore the database to its pre-transaction state.
Atomicity plays a crucial role in maintaining data integrity in multi-user environments. When multiple transactions are executed concurrently, the atomicity property ensures that they don't interfere with each other. Each transaction is isolated and treated as if it's the only one executing, preventing data inconsistencies caused by concurrent modifications.
C for Consistency
Consistency is a fundamental property of relational databases. This property ensures that a database remains in a valid state before and after any transaction. In simpler terms, consistency guarantees that the database constraints are not violated during the execution of transactions and that the data remains accurate and valid at all times. Consistency is ensured by enforcing any database constraints before and after all transactions.
Consistency in a database comprises a couple of key concepts. Let's go through each of them:
Database constraints: These include constraints such as primary keys, foreign keys, unique keys, check constraints and more. These constraints define certain rules that the data in the database must adhere to. For instance, a uniqueness constraint on a certain column will ensure that all rows will have a unique value for that particular column in the database; a foreign key ensures that referential integrity is maintained between related tables in the database.
Atomicity: To ensure consistency in databases, atomicity is an essential ingredient. Only if transactions are atomic, can database integrity be maintained. For example, say a transaction involves two UPDATE statements, one succeeds while the other fails. If the successful UPDATE is persisted in the database, instead of the entire transaction being rolled back, inconsistencies in the data might arise, thus jeopardizing consistency in the database.
Serializability: Consistency is also closely related to the concept of serializability in transaction management. Serializability ensures that concurrent transactions do not interfere with each other's execution, maintaining consistency and correctness of data. Even if multiple transactions are executed simultaneously, the database should produce the same result as if they were executed sequentially.
Write-Ahead Logging (WAL): Many relational database management systems (RDBMS) use write-ahead logging to maintain consistency. Before any modification is made to the database, the RDBMS writes the changes to a transaction log in a durable manner. This log ensures that in case of system failure, the database can be recovered to a consistent state using the log records.
Validation and Rollback: When a transaction is about to commit, the database management system verifies that all constraints are satisfied. If any constraint violation is detected, the transaction is rolled back, and the changes are not applied to the database. This prevents inconsistent or invalid data from entering the database.
Constraints Propagation: When a transaction modifies data, the changes may affect other tables due to cascading updates or deletes. The database management system ensures that the changes cascade correctly, maintaining data consistency throughout the database.
Locking Mechanisms: To maintain consistency during concurrent transactions, databases use various locking mechanisms to control access to data. Locks prevent multiple transactions from modifying the same data simultaneously, avoiding conflicts and ensuring the correct execution order.
All the above-mentioned measures ensure that consistency is maintained in all relational databases.
I for Isolation
Isolation ensures that each transaction in a database is executed in isolation from any other transactions that might be running concurrently as if it was the only transaction being run on the system. The goal of isolation is to prevent interference and conflicts among transactions, maintaining the illusion that transactions are executed sequentially, instead of concurrently.
Let's take an example to clarify this situation. Consider the following table.
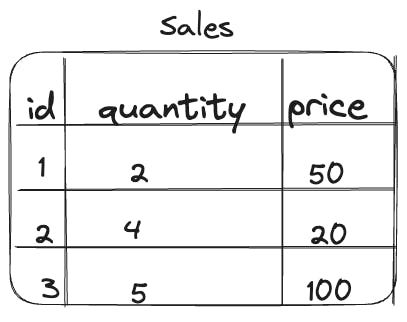
Now consider two transactions happening on this data.
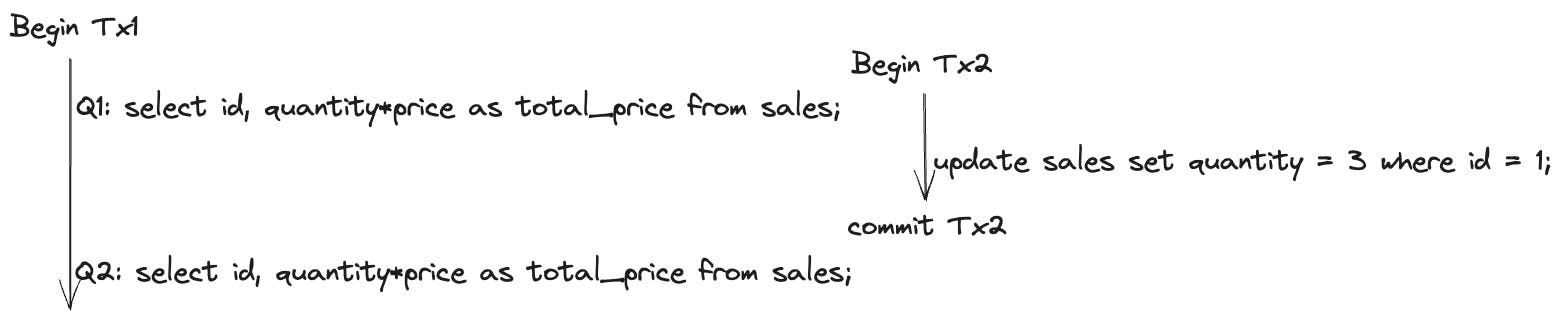
Consider the results of these queries. The query Q1 in Tx1 will return the data for the products with ids 1,2 and 3, like so:

Now, while Tx1 is still not finished executing, another transaction Tx2 begins, and an update query is run. The quantity value for the row with id 1 is updated to 3. This transaction is committed to the database.
Consider if the changes made by the transaction Tx2 are visible to Tx1. The results of the query Q2 in Tx1 will take into account the changes made by Tx2. This would cause an inconsistency in the results returned by Q1 and Q2. The results returned by Q2 would look like this:

Problems such as the one described above are called read phenomena. There are four kinds of read phenomena:
Dirty Reads
A dirty read occurs when a transaction reads data that has been written by another transaction but has not yet been committed. This can lead to the transaction seeing incorrect data, as the other transaction may later roll back its changes.
An example illustrating a dirty read can be constructed out of the Sales table illustration we saw earlier. Consider if the transaction
Tx2had executed the insert query before bothQ1andQ2, but hadn't committed the results yet.If the transaction
Tx1saw the modified data, there could be a scenario when a dirty read occurs. The queryQ1will return data as modified byTx2.If, before
Q2executes,Tx2rolls back the changes it made,Q2will return a result inconsistent withQ1. That would be a dirty read.Non-Repeatable Reads
A non-repeatable read occurs when a transaction reads the same data twice and sees different values. This can happen if another transaction updates the data between the two reads.
The
Salestable illustration we saw earlier is a case of a non-repeatable read.Phantom Reads
A phantom read occurs when a transaction executes a query twice and sees different results, even though the query itself has not changed. This can happen if another transaction inserts or deletes rows between the two queries.
An example of this would be if in the
Salestable illustration we saw earlier, an insert or a delete query would have been executed instead of an update query byTx2.Though this might seem a bit similar to a non-repeatable read, there is one key difference. In a non-repeatable read, the data that is read changes between the two reads. For example, a transaction might read the value of a column as 10, then read the value of the column again as 5. This is because another transaction updated the value of the column between the two reads.
In a phantom read, the data that is read does not change, but the number of rows that are returned by the query changes. For example, a transaction might read all rows from a table where the
quantitycolumn is greater than 5. There are 10 rows. Then, another transaction inserts a new row into the table where thequantitycolumn is greater than 5. When the first transaction re-reads the table, there are now 11 rows. This is because the second transaction inserted a new row into the table that met the criteria of the query.Serialization Anomaly
A serialization anomaly occurs when two transactions are trying to update the same data and one transaction is blocked from doing so because the other transaction has not yet committed its changes. This can lead to a deadlock, where neither transaction can proceed.
To solve the problems caused by these read phenomena, different isolation levels can be employed. An isolation level determines how much isolation is provided between concurrent transactions. Keep in mind, different databases have different implementations of isolation levels. We will cover these isolation levels for MySQL:
Read Uncommitted
This isolation level allows all four read phenomena to occur. This is the lowest isolation level and should be used with maximum caution as it can lead to incorrect data.
Read Committed
This isolation level prevents dirty reads. All other phenomena are still possible. At this isolation level, a transaction can only read data that has been committed by another transaction. This isolation level is a good compromise between performance and isolation.
Repeatable Read
Repeatable read prevents dirty reads, non-repeatable reads and phantom reads. This means that a transaction can read the same data multiple times and get the same results. It basically makes sure that when a query reads a row, that row will remain unchanged while the transaction is running.
Serializable
Serializable prevents all four read phenomena. This means that a transaction can see the same data as any other transaction that is currently running. This is the highest isolation level and provides the most protection from incorrect data, but it can also impact performance because the transactions are run as if they are serialized one after the other.
Database isolation is an immensely vast topic, and I'd recommend this article if you're interested in reading about it further. For now, let's move on to the last letter of today's topic.
D for Durability
Durability is the fourth property of ACID and it ensures that the changes made by a transaction are permanent. This is important because it guarantees that the data in the database is always reliable.
There are several ways to achieve durability in ACID. One common approach is to use checkpointing. Checkpointing involves periodically writing the state of the database to disk. This ensures that if the database crashes, the most recent state of the database can be restored from disk.
Another common approach to durability is to use log-based recovery. Log-based recovery involves maintaining a log of all changes made to the database. If the database crashes, the log can be used to replay the changes made to the database since the last checkpoint. This ensures that the database can be restored to the state it was in before the crash.
Here are some of the benefits of durability in ACID databases:
Data integrity: Durability ensures that data in the database is always consistent and accurate. This is important for applications that rely on the database for critical data.
Reliability: Durability ensures that the data in the database is always available, even in the event of a system failure or crash. This is important for applications that need to be highly available.
Performance: Durability can improve performance in some cases. For example, log-based recovery can improve performance by reducing the amount of data that needs to be written to disk.
Here are some of the challenges of durability in ACID databases:
Cost: Durability can add to the cost of an ACID database. For example, checkpointing and log-based recovery can require additional disk space and processing power.
Complexity: Durability can add to the complexity of an ACID database. For example, log-based recovery can be complex to implement and manage.
Performance: Durability can impact performance in some cases. For example, checkpointing and log-based recovery can add overhead to database operations.
Conclusion
That brings us to the end of this blog post. I hope you had a fun time learning about the ACID properties that are paramount to the operation of relational databases. Let me know in the comments if you have any questions about these topics!